Start with Architecture, Not Code
In 2025, "vibe coding" meant typing a prompt and watching an AI generate something. In 2026, the industry has a name for why that breaks on real projects: Spec-Driven Development. AWS shipped Kiro, an IDE built around a Specify → Plan → Execute workflow. GitHub's open-source Spec Kit crossed 84,000 stars. Analysts counted 30+ competing spec-first frameworks by March 2026.
They're all converging on the same insight: the more context a task requires, the worse an agent performs when you just hand it a prompt and hope.
You don't need Kiro or Spec Kit to apply the lesson. A plain ARCHITECTURE.md at the root of your repo does most of the work. FIRE51 was built this way, end to end.
The Mistake I Made First
Building FIRE51, the first thing I did wrong was skip this. I asked Claude to build the simulation engine before the data contracts between modules were defined. Each individual decision sounded reasonable — sensible types, clean function signatures, plausible JSON shapes. Two sessions later, when the engine output hit the report builder, nothing fit. Field names didn't match. Units were implicit in one module and explicit in the other. Two days of refactoring to align three modules that would have cost two hours of upfront interface design.
The AI didn't make bad decisions. It made uncoordinated decisions, because nothing told it what the other modules expected.
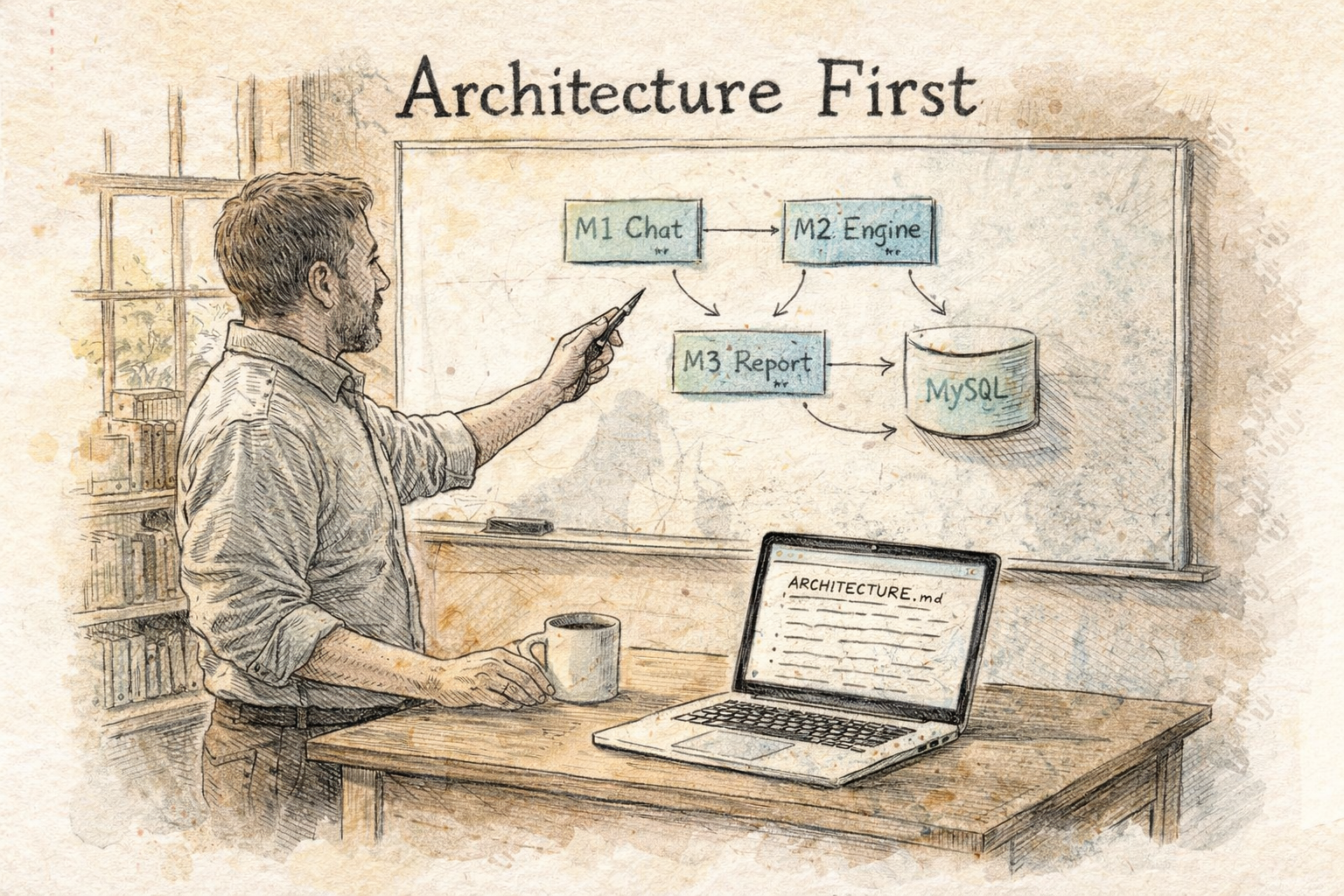
What Architecture-First Looks Like
Before any implementation, ARCHITECTURE.md should answer four questions:
- Module boundaries — what each part owns, and nothing more
- Data contracts — the JSON shape crossing each boundary
- Technology choices and their rationale
- Explicit out-of-scope — what this project does not do
With that document in place, every implementation request has a reference point. "Build Module 2 to consume the output defined in §Interface M1→M2." No invented decisions. No silent drift.
FIRE51's topology, literally taken from its ARCHITECTURE.md:
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ Web Browser │ │ iOS App │ │ Android App │
└───────┬───────┘ └───────┬───────┘ └───────┬───────┘
│ HTTPS/JWT │ HTTPS/JWT │ HTTPS/JWT
└──────────────────┼──────────────────┘
▼
┌────────────────────────┐
│ API Server (Express) │
│ ┌──────┐ ┌──────┐ │
│ │ M1 │ │ M3 │ │ ← Chat / Report
│ └──┬───┘ └──▲───┘ │
│ │ SimInput │ │
│ ▼ │ │
│ ┌────────────────┐ │
│ │ M2: Engine │ │ ← pure TypeScript
│ │ (no I/O, no DOM)│ │
│ └────────────────┘ │
│ │
│ MySQL: users, reports │
└─────────────────────────┘
One backend, three front-ends. The rule written next to the diagram: the calculation engine and database never run on the client. Every later architectural question got answered against this single picture.
How FIRE51 Used It
Before the first server file, five modules were defined with named interface contracts:
- Input collection — chat-driven Q&A, outputs
SimInput - Simulation engine — pure TypeScript, no I/O, consumes
SimInput, produces yearly ledger - Report output — consumes the ledger, renders HTML/charts/PDF
- Recommendations — scenario comparison across ledgers
- PolicyEngine tax validator — external ground truth for the engine
The annual simulation loop had a written step order: income → expenses → RMD → Roth conversion → tax → withdrawals → growth → flagging. That single sentence prevented countless bugs. Without it, the AI would have reordered steps based on whatever felt intuitive that session.
When the engine was complete, integration had zero surprises. Every module consumed exactly what the upstream module produced, because the interfaces were frozen before either side was written.
Keeping the Document Honest
The second discipline is less obvious and more important: update the architecture document before changing the code, not after.
"According to ARCHITECTURE.md §3, this is out of scope" is a complete answer to AI scope creep. It's also a complete answer to your own temptation to sneak features in mid-sprint. The document gives you something to point at.
When the AI proposes something inconsistent with the document, that's a real decision point. Either update the architecture intentionally — with a sentence of rationale — or push back on the proposal. Both are fine. Silent drift is not.
The Practical Rule
Start with a blank file. Write what you're building, what you're not building, where the module boundaries are, and what the data shapes look like across them. It doesn't need to be long. FIRE51's initial ARCHITECTURE.md was under 200 lines.
The AI reads it at the start of every session. The architecture stays in scope. Integration surprises stay small. And you stop rediscovering the same design decisions in session three that you already made in session one.
Spec-Driven Development is where the industry is heading for exactly this reason. The tooling will get slicker, the formats will standardize. But the core move — write the map before you drive — has been the right answer since long before AI could write code, and it will still be the right answer after.
FIRE51 is a retirement planning tool built entirely via vibe coding. This is the fourth post in the Vibe Coding series.